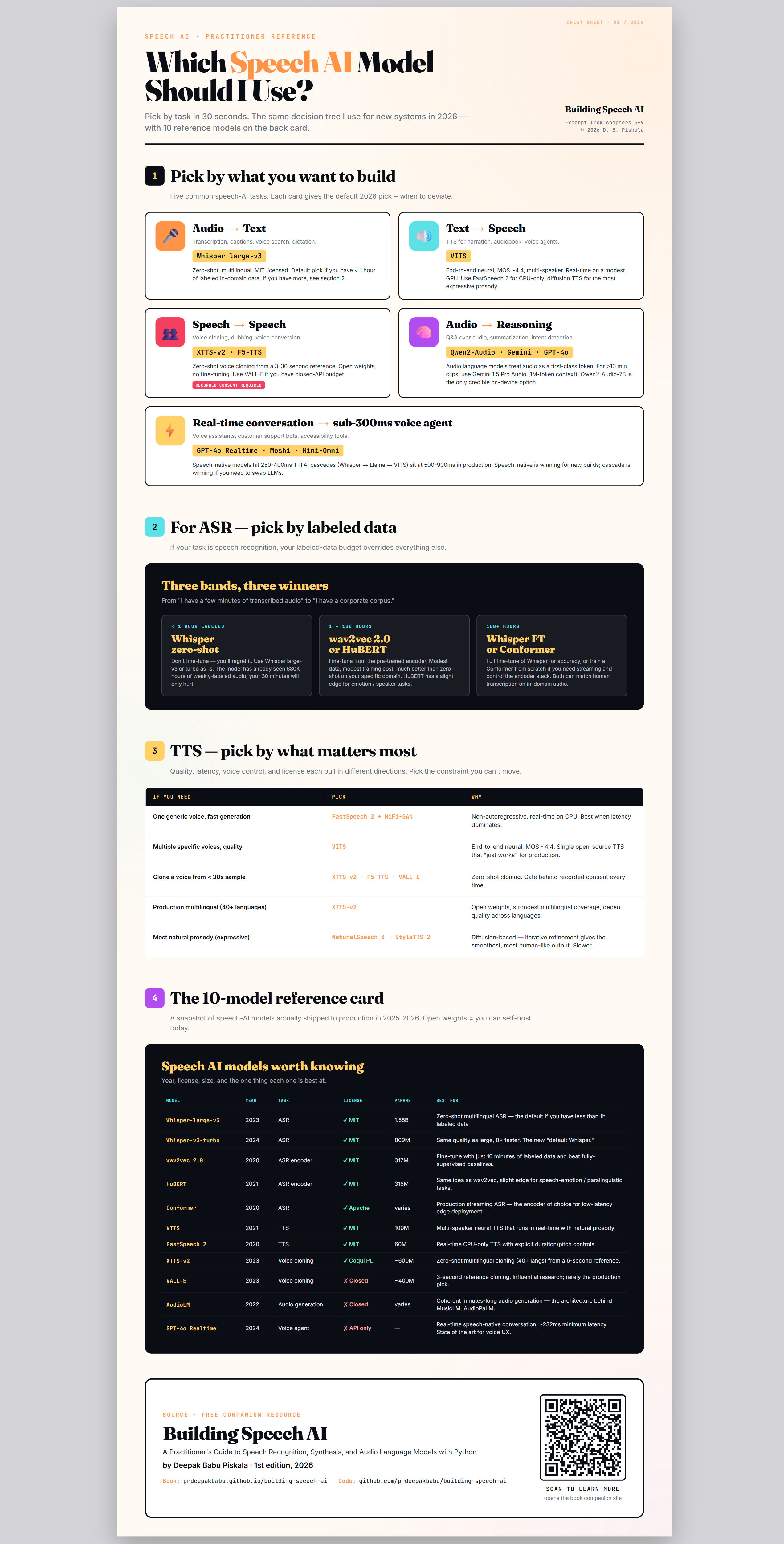
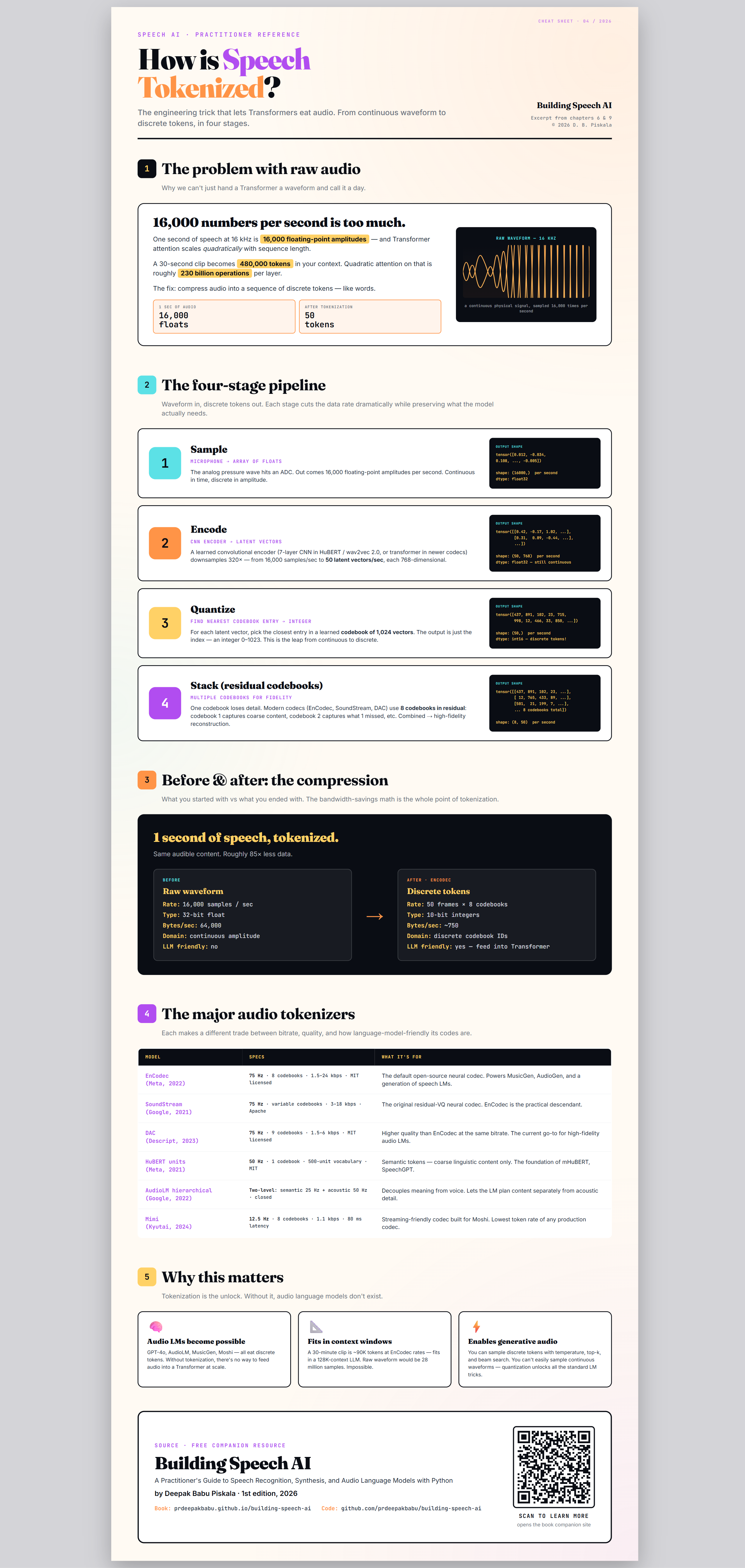
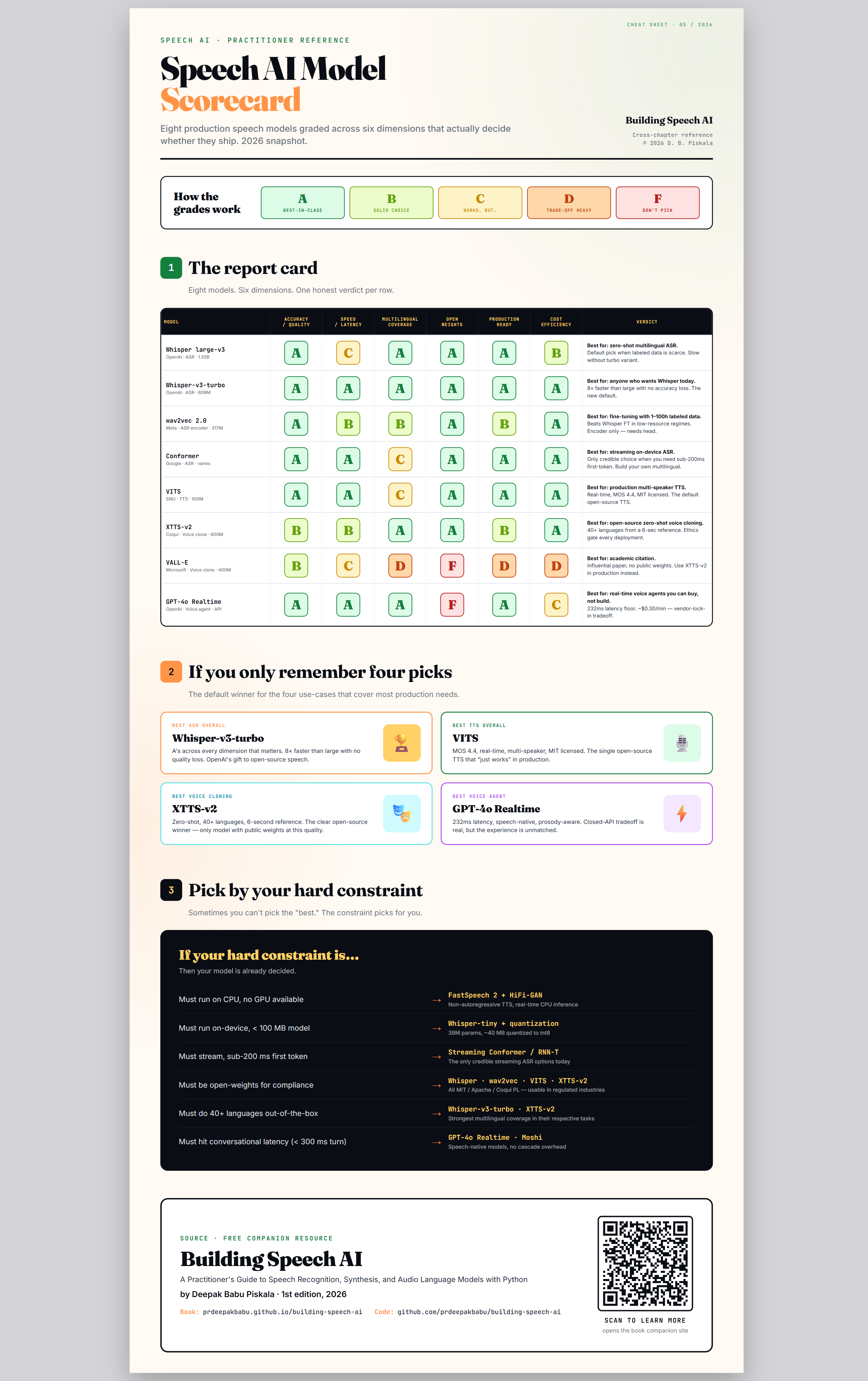
Speech AI sits at an unusual intersection: signal processing, linguistics, machine learning, and systems
engineering. Academic papers assume you know Fourier analysis; DSP textbooks ignore neural networks; ML
courses treat audio as just another input modality.
This is a builder's book. Whether you're a machine-learning engineer exploring audio for the first time,
a software developer integrating voice into a product, a researcher pushing state of the art, or a technical
leader evaluating voice strategies — you'll find the conceptual foundations and the practical
implementations together.
“If you can't run it, you don't really understand it.”
Every concept ships with working code. Not toy examples, but real implementations you can run, modify,
and extend. We resist the temptation to hide complexity behind library calls. When we use Whisper or
wav2vec 2.0, we understand what's happening inside.